前言
有些小伙伴在工作中,可能经常遇到这样的场景:系统上线初期运行良好,随着数据量增长,突然某天接口超时、CPU飙升、甚至整个系统瘫痪。
排查半天,发现是某个SQL语句写的有问题,或者是数据库配置不当导致的。
今天这篇文章我就从浅入深,带你彻底避开MySQL的6大常见雷区,希望的对你会有所帮助。
为什么MySQL雷区如此之多?
在深入具体雷区之前,我们先聊聊为什么MySQL这么容易踩坑。
这背后有几个深层次原因:
看似简单:MySQL语法简单,入门容易,让很多人低估了它的复杂性
默认配置坑多:MySQL的默认配置往往不是最优的,需要根据业务场景调整
渐进式问题:很多问题在数据量小的时候不会暴露,等到暴露时已经为时已晚
知识更新快:从5.6到5.7再到8.0,每个版本都有重要变化,需要持续学习
有些小伙伴在工作中,可能直接用默认配置部署MySQL,或者在写SQL时只关注功能实现,忽略了性能问题。
这就是为什么我们需要系统性地了解这些雷区。
好了,让我们开始今天的主菜。我将从最常见的索引失效,逐步深入到复杂的死锁问题,确保每个雷区都讲透、讲懂。
雷区一:索引失效的常见场景
索引是MySQL性能的基石,但错误的使用方式会让索引失效,导致全表扫描。
这是最常见的性能雷区。
为什么索引会失效?
索引失效的本质是MySQL优化器认为使用索引的成本高于全表扫描。
了解这些场景,可以帮助我们写出更高效的SQL。
示例场景:
-- 创建测试表
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
age INT,
email VARCHAR(100),
created_time DATETIME,
INDEX idx_name (name),
INDEX idx_age (age),
INDEX idx_created_time (created_time)
);
-- 雷区1.1:对索引列进行函数操作
-- 错误写法:索引失效
EXPLAIN SELECT * FROM user WHERE DATE(created_time) = '2023-01-01';
-- 正确写法:使用范围查询
EXPLAIN SELECT * FROM user
WHERE created_time >= '2023-01-01 00:00:00'
AND created_time < '2023-01-02 00:00:00';
-- 雷区1.2:隐式类型转换
-- 错误写法:name是字符串,但用了数字,导致索引失效
EXPLAIN SELECT * FROM user WHERE name = 123;
-- 正确写法:类型匹配
EXPLAIN SELECT * FROM user WHERE name = '123';
-- 雷区1.3:前导模糊查询
-- 错误写法:LIKE以%开头,索引失效
EXPLAIN SELECT * FROM user WHERE name LIKE '%三%';
-- 正确写法:非前导模糊查询,可以使用索引
EXPLAIN SELECT * FROM user WHERE name LIKE '苏%';
-- 雷区1.4:OR条件使用不当
-- 错误写法:age有索引,email无索引,导致整个查询无法使用索引
EXPLAIN SELECT * FROM user WHERE age = 25 OR email = 'test@example.com';
-- 正确写法:使用UNION优化OR查询
EXPLAIN
SELECT * FROM user WHERE age = 25
UNION
SELECT * FROM user WHERE email = 'test@example.com';
深度剖析
有些小伙伴在工作中可能会疑惑:为什么这些写法会导致索引失效?
函数操作破坏索引有序性
索引是按照列值的原始顺序存储的
对列使用函数后,MySQL无法利用索引的有序性
必须扫描所有索引项,计算函数值后再比较
隐式类型转换的本质
前导模糊查询的B+树遍历
B+树索引按照前缀排序
LIKE '苏%'可以利用前缀匹配
LIKE '%三'无法确定前缀,必须全表扫描
避坑指南
避免对索引列进行函数操作
确保查询条件与索引列类型匹配
谨慎使用前导模糊查询
使用UNION优化复杂的OR查询
雷区二:事务隔离级别与幻读
事务隔离级别是MySQL中比较复杂的概念,理解不当会导致数据不一致和性能问题。
为什么事务隔离级别重要?
不同的隔离级别在数据一致性、性能、并发性之间做出不同权衡。
选择不当会出现脏读、不可重复读、幻读等问题。
示例场景:
-- 查看当前事务隔离级别
SELECT @@transaction_isolation;
-- 设置隔离级别为REPEATABLE-READ(默认)
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 场景:转账业务中的幻读问题
-- 会话1:事务A
START TRANSACTION;
SELECT COUNT(*) FROM account WHERE user_id = 1001; -- 返回2
-- 会话2:事务B
START TRANSACTION;
INSERT INTO account (user_id, balance) VALUES (1001, 500);
COMMIT;
-- 会话1:事务A继续
SELECT COUNT(*) FROM account WHERE user_id = 1001; -- 仍然返回2(可重复读)
UPDATE account SET balance = balance + 100 WHERE user_id = 1001; -- 影响3行!
SELECT COUNT(*) FROM account WHERE user_id = 1001; -- 返回3,出现幻读!
COMMIT;
深度剖析
有些小伙伴在工作中可能遇到过:明明查询时不存在的数据,更新时却影响到了。这就是典型的幻读问题。
幻读的本质:
MySQL的解决方案:
为了理解间隙锁的工作原理,我画了一个锁范围示意图:
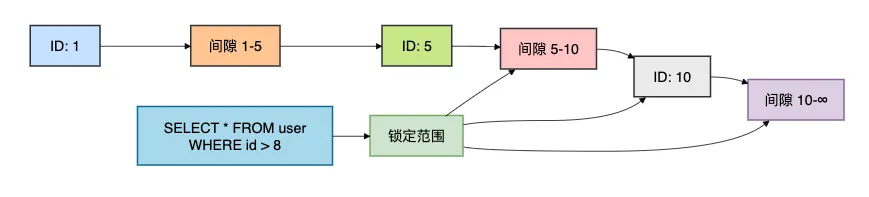
这个图展示了当查询id > 8时,MySQL会锁定[5,10]的间隙、ID=10的记录,以及[10,∞]的间隙,防止其他事务插入ID>8的数据。
避坑指南
雷区三:大数据量下的分页优化
分页查询是Web应用中最常见的操作,但在大数据量下性能急剧下降。
为什么分页会变慢?
LIMIT offset, size在offset很大时,需要扫描并跳过大量记录,造成性能瓶颈。
示例场景:
-- 创建测试表,假设有1000万数据
CREATE TABLE order (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
amount DECIMAL(10,2),
status TINYINT,
created_time DATETIME,
INDEX idx_created_time (created_time)
);
-- 雷区:传统的分页写法
-- 当offset达到500万时,性能急剧下降
EXPLAIN SELECT * FROM order
ORDER BY created_time DESC
LIMIT 5000000, 20;
-- 优化方案1:游标分页(推荐)
-- 第一页
SELECT * FROM order
ORDER BY created_time DESC, id DESC
LIMIT 20;
-- 第二页:记住上一页最后一条记录的created_time和id
SELECT * FROM order
WHERE created_time < '2023-06-01 10:00:00'
OR (created_time = '2023-06-01 10:00:00' AND id < 1000000)
ORDER BY created_time DESC, id DESC
LIMIT 20;
-- 优化方案2:子查询优化(适用于非游标场景)
SELECT * FROM order
WHERE id >= (
SELECT id FROM order
ORDER BY created_time DESC
LIMIT 5000000, 1
)
ORDER BY created_time DESC
LIMIT 20;
深度剖析
有些小伙伴在工作中可能发现,为什么offset越大查询越慢?
传统分页的性能瓶颈:
- 大量无效IO:需要读取并跳过offset条记录
- 回表成本:对于非覆盖索引,需要回表查询完整数据
- 排序开销:大数据量的排序可能在磁盘进行
游标分页的优势:
- 直接定位到起始位置,无需跳过大量记录
- 利用索引的有序性,避免排序操作
- 性能稳定,不随数据量增长而下降
为了理解传统分页与游标分页的区别,我画了一个对比图:
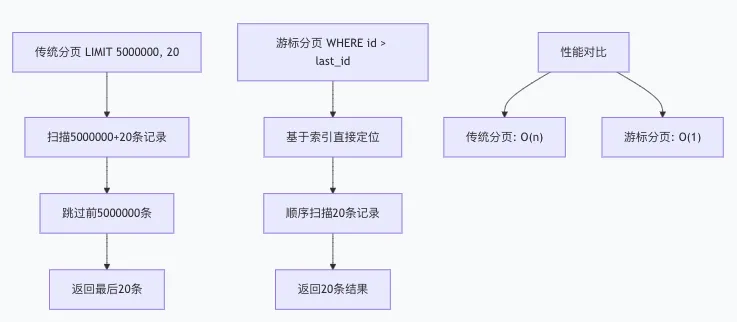
避坑指南
- 优先使用游标分页(基于游标或时间戳)
- 如果必须使用传统分页,使用子查询优化
- 确保排序字段有索引
前端配合使用无限滚动或游标分页UI
雷区四:字符集与排序规则陷阱
字符集问题经常在系统国际化或多语言支持时暴露,处理不当会导致乱码、排序错误、索引失效。
为什么字符集如此重要?
不同的字符集支持不同的字符范围,排序规则影响字符串比较和排序结果。
示例场景:
SHOW VARIABLES LIKE 'character_set%';
SHOW VARIABLES LIKE 'collation%';
-- 雷区:UTF8不是真正的UTF-8
-- MySQL的utf8最多支持3字节,无法存储emoji等4字节字符
CREATE TABLE user_utf8 (
id INT PRIMARY KEY,
name VARCHAR(50) CHARACTER SET utf8
);
-- 插入emoji表情失败
INSERT INTO user_utf8 VALUES (1, '张三😊'); -- 错误!
-- 正确:使用utf8mb4
CREATE TABLE user_utf8mb4 (
id INT PRIMARY KEY,
name VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci
);
-- 插入emoji成功
INSERT INTO user_utf8mb4 VALUES (1, '张三😊'); -- 成功!
-- 雷区:排序规则影响查询结果
CREATE TABLE product (
id INT PRIMARY KEY,
name VARCHAR(100)
) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
-- 大小写不敏感查询
SELECT * FROM product WHERE name = 'apple'; -- 会匹配'Apple', 'APPLE'
-- 如果需要大小写敏感,使用binary或特定collation
SELECT * FROM product WHERE name = BINARY 'apple'; -- 只匹配'apple'
深度剖析
有些小伙伴在工作中可能遇到过存储emoji失败,或者查询时大小写匹配异常,这都是字符集配置不当导致的。
UTF8 vs UTF8MB4:
- utf8:MySQL历史上的"假UTF-8",最多3字节,不支持emoji、部分中文生僻字
- utf8mb4:真正的UTF-8实现,支持4字节,推荐使用
排序规则的影响:
_ci结尾:大小写不敏感(Case Insensitive)_cs结尾:大小写敏感(Case Sensitive)_bin结尾:二进制比较,完全匹配
为了理解不同字符集的存储范围,我画了一个对比图:
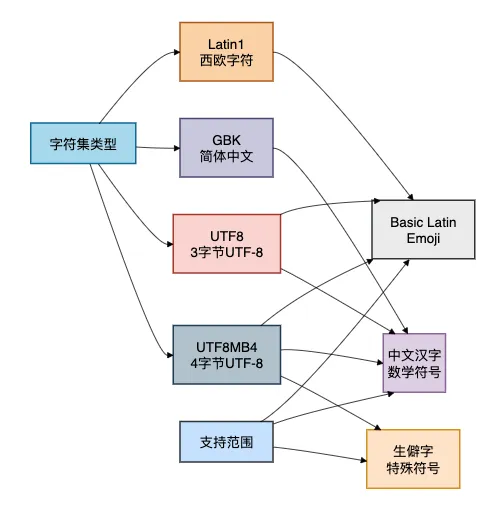
避坑指南
- 新项目一律使用utf8mb4字符集
- 根据业务需求选择合适的排序规则
- 数据库、表、字段、连接字符集保持一致
迁移现有数据时注意字符集转换
雷区五:外键与级联操作的隐患
外键约束可以保证数据完整性,但使用不当会带来性能问题和复杂的维护成本。
为什么外键是双刃剑?
外键在保证数据一致性的同时,会带来锁竞争、维护复杂、迁移困难等问题。
示例场景:
-- 创建带外键的表结构
CREATE TABLE department (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL
);
CREATE TABLE employee (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
department_id INT,
FOREIGN KEY (department_id)
REFERENCES department(id)
ON DELETE CASCADE
ON UPDATE CASCADE
);
-- 雷区1:级联删除导致意外数据丢失
-- 删除部门时,所有相关员工也被删除,可能不是期望的行为
DELETE FROM department WHERE id = 1; -- 部门1的所有员工都被删除!
-- 雷区2:外键锁竞争
-- 会话1:删除部门
START TRANSACTION;
DELETE FROM department WHERE id = 1; -- 持有部门1的锁
-- 会话2:在同一个部门插入员工(被阻塞)
START TRANSACTION;
INSERT INTO employee (name, department_id) VALUES ('新员工', 1); -- 等待锁
-- 雷区3:数据迁移困难
-- 导入数据时必须按正确顺序,否则外键约束失败
深度剖析
有些小伙伴在工作中可能发现,系统并发量上来后,经常出现锁等待超时,外键约束是常见原因之一。
外键的性能影响:
- 锁范围扩大:操作父表时需要检查子表,可能锁定更多数据
- 死锁风险:多表之间的外键关系容易形成死锁环路
- 并发下降:外键检查需要额外加锁,降低系统并发能力
级联操作的风险:
ON DELETE CASCADE:误删父表记录会导致大量子表数据丢失ON UPDATE CASCADE:更新主键时传播到所有子表,性能影响大
为了理解外键锁的竞争关系,我画了一个锁等待示意图:
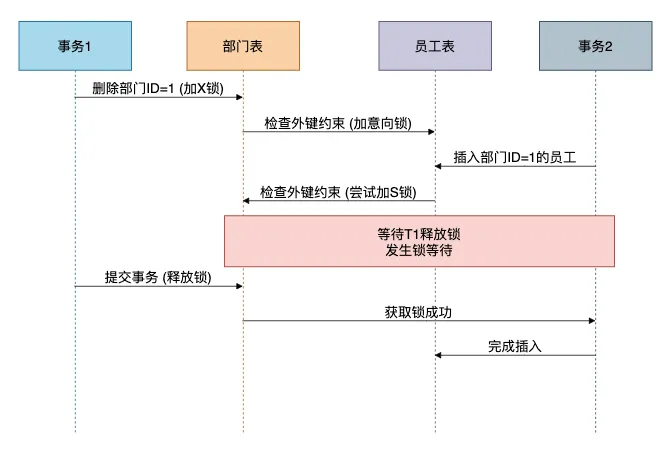
避坑指南
- 高并发场景慎用外键,可在应用层保证数据一致性
- 如果使用外键,避免ON DELETE/UPDATE CASCADE
- 使用软删除替代物理删除
批量操作时暂时禁用外键检查
雷区六:连接池配置不当
连接池配置看似简单,实则影响整个系统的稳定性和性能。
配置不当会导致连接泄露、池化失效等问题。
为什么连接池如此关键?
数据库连接是宝贵的资源,创建和销毁成本很高。
连接池管理不当会直接导致系统崩溃。
示例场景:
// Spring Boot中的Druid连接池配置
@Configuration
public class DruidConfig {
@Bean
@ConfigurationProperties("spring.datasource.druid")
public DataSource dataSource() {
return DruidDataSourceBuilder.create().build();
}
}
// application.yml配置
spring:
datasource:
druid:
# 雷区1:初始连接数过大,浪费资源
initial-size: 50
# 雷区2:最大连接数过小,并发时等待
max-active: 20
# 雷区3:最小空闲连接数不合理
min-idle: 5
# 雷区4:获取连接超时时间过短
max-wait: 3000
# 雷区5:没有配置连接有效性检查
validation-query: SELECT 1
test-on-borrow: true
test-on-return: false
test-while-idle: true
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
深度剖析
有些小伙伴在工作中可能遇到过连接池耗尽、连接泄露等问题,这都是配置不当导致的。
连接池的核心参数:
连接泄露的检测与预防:
// 常见的连接泄露模式
public class UserService {
// 错误写法:连接未关闭
public User getUser(int id) {
Connection conn = dataSource.getConnection();
// 执行查询...
// 忘记调用conn.close()
return user;
}
// 正确写法:使用try-with-resources
public User getUserCorrect(int id) {
try (Connection conn = dataSource.getConnection();
PreparedStatement stmt = conn.prepareStatement("SELECT * FROM user WHERE id = ?")) {
stmt.setInt(1, id);
ResultSet rs = stmt.executeQuery();
// 处理结果...
return user;
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
为了理解连接池的工作机制,我画了一个连接池状态转换图:
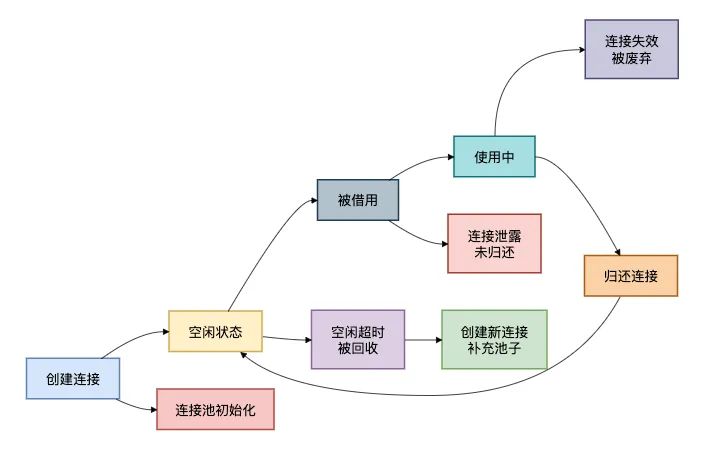
避坑指南
- 根据业务压力合理配置连接池参数
- 使用try-with-resources确保连接关闭
- 开启连接泄露检测功能
- 监控连接池状态,设置合理的告警阈值
总结
经过以上6大雷区的分析,相信你对MySQL的常见坑点有了更深入的理解。
雷区对比总结:
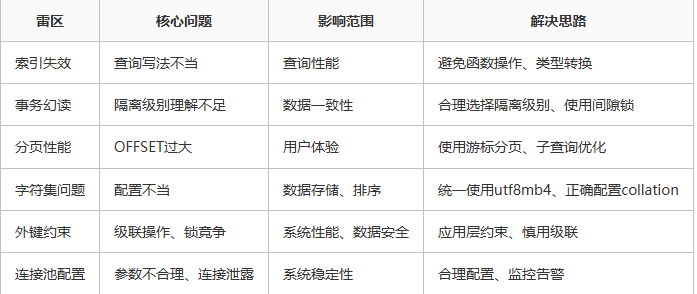
参考文章:原文链接
该文章在 2025/10/31 16:11:35 编辑过






 400 186 1886
400 186 1886


